Add Tabular Diff for CSV files #14661
Labels
No Label
backport/done
backport/v1.0
backport/v1.1
backport/v1.10
backport/v1.11
backport/v1.12
backport/v1.13
backport/v1.14
backport/v1.15
backport/v1.2
backport/v1.3
backport/v1.4
backport/v1.5
backport/v1.6
backport/v1.7
backport/v1.8
backport/v1.9
bounty
changelog
dependencies
frontport/done
frontport/main
good first issue
Hacktoberfest
hacktoberfest-accepted
in progress
kind/api
kind/breaking
kind/bug
kind/build
kind/deployment
kind/deprecated
kind/docs
kind/enhancement
kind/feature
kind/lint
kind/misc
kind/moderation
kind/package
kind/proposal
kind/question
kind/refactor
kind/regression
kind/security
kind/summary
kind/testing
kind/translation
kind/ui
kind/upstream-related
kind/usability
kind/ux
lgtm/done
lgtm/need 1
lgtm/need 2
performance/bigrepo
performance/cpu
performance/memory
performance/speed
priority/critical
priority/low
priority/maybe
priority/medium
proposal/rejected
reviewed/confirmed
reviewed/duplicate
reviewed/fixed
reviewed/invalid
reviewed/not-a-bug
reviewed/wontfix
skip-changelog
stale
status/blocked
status/needs-feedback
status/wip
theme/2fa
theme/authentication
theme/avatar
theme/backup-restore
theme/docker
theme/federation
theme/issues
theme/kanban
theme/markdown
theme/migration
theme/mobile
theme/pr
theme/signing
theme/sqlite
theme/timetracker
theme/webhook
theme/wiki
No Milestone
No project
No Assignees
2 Participants
No due date set.
Dependencies
No dependencies set.
Reference: lunny/gitea#14661
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "feature-csv-diff"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Implements request #14320 The rendering of csv files does match the diff style.
A simple change:

Changes in different areas (note the jumping line numbers):

A removed column is rendered without marking all rows as changed:

Toggle view:

@ -68,3 +150,4 @@// ParseCompareInfo parse compare info between two commit for preparing comparing referencesfunc ParseCompareInfo(ctx *context.Context) (*models.User, *models.Repository, *git.Repository, *git.CompareInfo, string, string) {baseRepo := ctx.Repo.RepositoryThis reader is unbound in size. There's no reason why that couldn't simply read in 100Mb straight in to memory.
This is also an unbound read.
And this.
@ -68,3 +150,4 @@// ParseCompareInfo parse compare info between two commit for preparing comparing referencesfunc ParseCompareInfo(ctx *context.Context) (*models.User, *models.Repository, *git.Repository, *git.CompareInfo, string, string) {baseRepo := ctx.Repo.RepositoryI have ignored this because this code doesn't run if the diff decides "file too large". Anyway the max file size is restricted to 512kb now like on GitHub.
Why not keep these code still in package
modules/markup/csv/?I thought the csv reader creation logic shouldn't be coupled with the render part.
I'm OK with another package but put them in
basepackage seems not suitable. Maybe we can create a new package namedmodules/csvor similar to do that.I moved the code to a new csv package.
@ -0,0 +56,4 @@}// scoreDelimiter uses a count & regularity metric to evaluate a delimiter against lines of CSV.func scoreDelimiter(lines []string, delim rune) float64 {How did you handle
"a,b"\t"c,b"?@ -0,0 +38,4 @@maxBytes := util.Min(len(data), 1e4)text := string(data[:maxBytes])text = quoteRegexp.ReplaceAllLiteralString(text, "")lines := strings.SplitN(text, "\n", maxLines+1)"a\nb","c"?@ -0,0 +56,4 @@}// scoreDelimiter uses a count & regularity metric to evaluate a delimiter against lines of CSV.func scoreDelimiter(lines []string, delim rune) float64 {This is not for this PR since it's only a refactor.
@ -0,0 +38,4 @@maxBytes := util.Min(len(data), 1e4)text := string(data[:maxBytes])text = quoteRegexp.ReplaceAllLiteralString(text, "")lines := strings.SplitN(text, "\n", maxLines+1)This is not for this PR since it's only a refactor.
@ -0,0 +56,4 @@}// scoreDelimiter uses a count & regularity metric to evaluate a delimiter against lines of CSV.func scoreDelimiter(lines []string, delim rune) float64 {I didn't change this code but first the regex deletes all quoted text and then the delimiter
\tis found.Original code:
0a9a484e1e/modules/markup/csv/csv.go (L67-L113)@ -0,0 +38,4 @@maxBytes := util.Min(len(data), 1e4)text := string(data[:maxBytes])text = quoteRegexp.ReplaceAllLiteralString(text, "")lines := strings.SplitN(text, "\n", maxLines+1)Same as above.
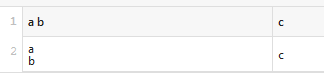
@ -250,1 +250,4 @@[ui.csv]; Maximum allowed file size in bytes to render CSV files as table. (Set to 0 for no limit).MAX_FILE_SIZE = 524288Why did you set 512 KB as default maximum?
@ -250,1 +250,4 @@[ui.csv]; Maximum allowed file size in bytes to render CSV files as table. (Set to 0 for no limit).MAX_FILE_SIZE = 524288I just adopted the value from Github.
Is this really related?
No, should this "fix" be another PR?
Yes, please
done #14949
Can you add a test for line deletion and line addition? Seems to display incorrectly when I tested:
I would use something a little higher, like 1.2. Gets a little squished with some fonts.
I have removed the line-height. Looks better without it.
Awesome. Thanks for adding unit tests! ?
Could you add also
@as delimiter?please also update year in other newly added files